Microsoft Cluster Services Across Hypervisors (vmware+huawei)
В данной статье рассматривается режим работы Microsoft Cluster Services, при котором ВМ работают на гипервизорах разных вендоров.
Администрируя vSphere 5.5 я ни под какими предлогами не допускал в инфраструктуру Microsoft Cluster Services (MSCS). Поскольку развернув кластер MSCS прочувствовал на себе все ограничения данной технологии, после чего отказался от ее использования.
Виртуальные машины кластера MSCS не мигрировали, висели на хосте, гордо заявляя: «Перезагрузка хоста ESXi только через наш труп!». Что сводило на нет многие плюсы виртуализации.
В vSphere 6 это ограничение было устранено — vMotion и MSCS подружились.
Что несомненно вдохнуло новую жизнь в использование технологии кластеризации Microsoft совместно с кластеризацией VMware.
В статье vMotion support for MSCS приводятся оставшиеся ограничения. Но как по мне — так ограничениями их считать нельзя.
Вообще существуют несколько реализаций кластера, которые описаны как в официальной документации — Setup for Failover Clustering and Microsoft Cluster Service, так и более понятно и компактно в статях, например MICROSOFT CLUSTERING WITH VMWARE VSPHERE DESIGN GUIDE.
В частности:
— Cluster In A Box (CIB): виртуальные машины размещены на одном хосте. При сбое одной ВМ кластеризованая служба, например файловый сервер, продолжает функционировать. Однако при сбое хоста мы имеем сбой и кластера MSCS.
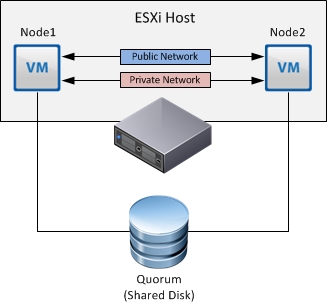
— Cluster Across Boxes (CAB): ВМ размещены на двух хостах, — соответственно при сбое одного хоста кластерная служба, продолжает функционировать.
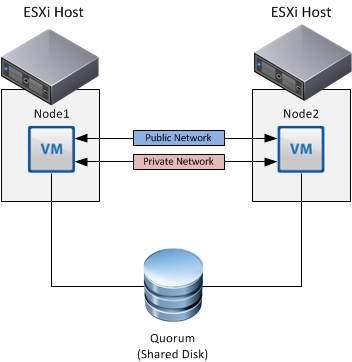
— Virtual Machine + Physical. Один из сценариев использования — это миграция кластера с физических хостов в виртуальную инфраструктуру.

Сравнение различных реализаций приведено в таблице:
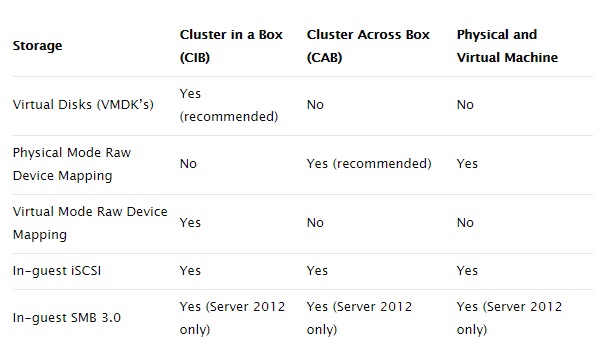
Итак, мы имеем очень полезную технологию, которая защищает одновременно и от сбоя хоста и от сбоя операционной системы. А также позволяет произвести легкую миграцию кластера MSCS из физической в виртуальную инфраструктуру.
И тут у меня возник вопрос: а только ли из физической? Ведь в реализациях Cluster Across Boxes (CAB) и Virtual Machine + Physical используется Raw Device Mapping (RDM).
Режим работы виртуальных дисков Raw Device Mapping (RDM) позволяет напрямую использовать блочное устройство хранения без создания на нем файловой системы VMFS.
И этот режим поддерживает не только гипервизор ESXi…
Так что мешает реализовать Cluster Across Hypervisors?
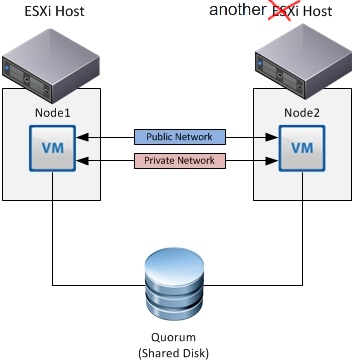
Поискав информацию о данном режиме, я ее …. не нашел.
Поэтому решил проверить на практике, использовав в качестве альтернативного гипервизора платформу Huawei FusionSphere.
Создал на двух гипервизорах две ВМ, презентовал хостам VMware и Huawei два луна — т.е. сам диск свидетель и диск для использования в качестве файловой шары. Прокинул их в ВМ как RDM диски и … кластер заработал.
Т.е. Cluster Across Hypervisors вполне себе имеет право на существование.
И да, миграция кластеризованной ВМ работает, притом в обоих гипервизорах.
Правда в случае с Huawei наличие RDM диска увеличивает время миграции примерно в три раза.
Для VMware наличие RDM диска никак не изменяет время миграции.
Владение виртуальной машины ролью, а также запись на файловую шару данных для обоих гипервизоров не изменяет время миграции, запись при этом конечно же прерывается.
При этом миграция виртуальных машин является стрессом для кластерной роли. Поэтому в условиях рабочих нагрузок перед проведением миграции виртуальной машины роль с нее нужно переносить средствами Диспетчера отказоустойчивости кластеров. Либо для восстановления работоспособности роли это необходимо делать уже после миграции
Вариант использования, как я писал выше — это перенос сервиса между гипервизорами разных вендоров без прерывания его работы. Правда работает это только в случае кластеризованного сервиса. И усилий необходимо приложить гораздо больше, чем просто миграция между гипервизорами одного вендора. С другой стороны если вам необходимо протестировать работу боевого кластера SQL на разных платформах, то опять же нет ничего проще. Просто запускаете роль на альтернативном гипервизоре и смотрите как она себя ведет в реальной обстановке. И в случае очень неудовлетворительных результатах просто переносите роль на другой узел отказоустойчивого кластера.



